
How I Synthesize Useful Datasets
And how you can create one for any use case


Note: This is a companion article to the one where I explain how I built a data pipeline for my synthesized data Breaking Down my Own Private Data Pipeline.
The Practical Need for Synthesized Data
I test many data tools to see if they can get me working within 5 minutes. A well-designed tool lets me connect to familiar data and start a workflow quickly. This requires using data I know well that has a clear objective. I obviously cannot go download data from a client I’m consulting, and downloading a Kaggle dataset means spending time understanding the dataset before you can use the tool effectively. What I do instead is synthesize clean datasets using AI and data pipelines.
Designing a dataset is fundamentally different from wrangling existing data sources. The modern data stack focuses on the latter, piecing together disparate sources with different formats through DAGs and pipelines. Engineering a data source from scratch is a distinct problem that requires a different approach.
On a practical level, data and analytics engineering can be time consuming and slow down projects. Waiting months on data engineering work before building metrics or reports creates a waterfall bottleneck. This delays milestones and disconnects engineering teams from customer-facing teams. Synthesizing the ideal dataset during data engineering work solves this problem.
Working Backwards to Design a Dataset
Before You Write a Single Prompt
A dataset isn’t just a table of values, it is the end result of a designed system. The most interesting part about designing a data model isn’t just the table you end up with. It’s having foresight into what you plan on doing with it. The values of that output drive metrics that feed into the KPI’s that help a company measure its definition of success.
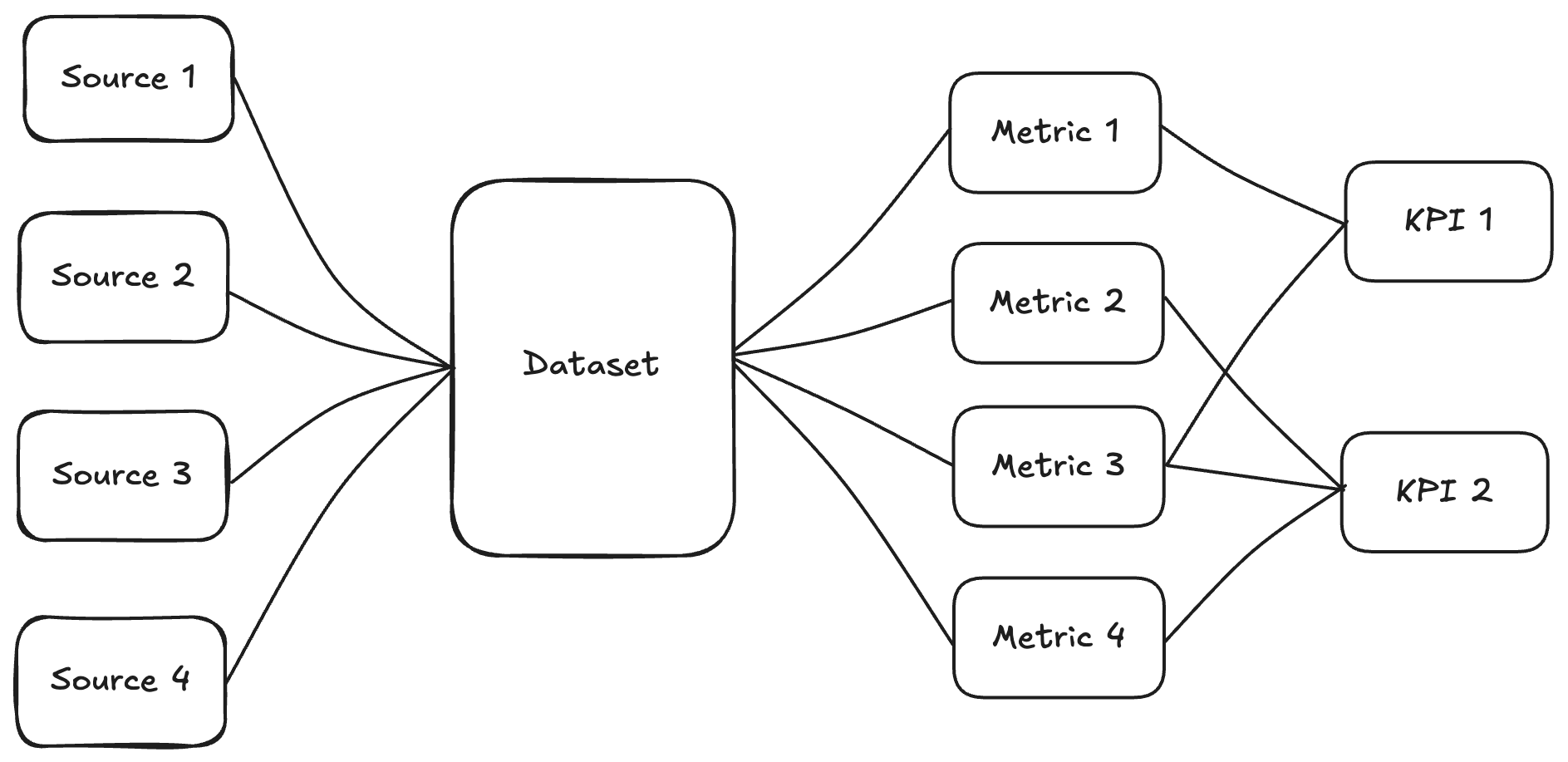
So before you try to think up a dataset, you want to first describe how success should be measured. This is “Analytics 101” but in the case of designing a dataset to synthesize it’s a really powerful way to get to the heart of what you need from it. The source tables, for example, can (an probably should) have literally everything that a data source has to offer when it comes to data attributes. The dataset you build from those sources though are best designed through business domains and the way that domain plays into the definition of success. I am a major proponent of domain driven design when it comes to analytical models. I am not as much of a fan of just creating “One Big Table”. I think analytical models should be built for a purpose that is contained within business context. This helps to connect them together downstream. That was a bit of a tangent, but important when it comes to how I design synthesized datasets.
Now, you might think defining KPI’s is “starting from the beginning” but it’s not. Before you understand what success looks like, you need to know what the actual company is that you need to define success for.
Create a Hypothetical Company
The first thing I do is to create a hypothetical company. When I’m testing out a tool, I normally use a dataset I built that is meant to synthesize user watch time for shows and movies using a made up streaming company. It’s a mental model I understand and can easily envision useful metrics/KPIs for. This gives me the ability to properly evaluate an LLM’s/Agent’s assessment of it and any corresponding analytics it returns. I already know the most important things that should be measured from it because I built it and already created those metrics before.
That takes a little imagination, but you’re at an advantage if you’d like to do this for the current company you work at. You can simply abstract your company (and the area you work in) into a hypothetical company attempting to do the exact same thing. For example, I was a Data Scientist at The Home Depot for four years. I worked primarily in the Pro Contracting business domain the entire time. My job was to build out usage and behavior models based on the activity we tracked in a web application that was used at the Pro Contractors desk in all Home Depot locations. Success for this area of the business was selling large projects to Pro Contractors using this application.
So when you think about things this way, the image above actually reverses. The hypothetical business becomes the “source” to where you then decide on success (KPIs) the metrics that measure that success and ultimately what a dataset would need to look like to build those metrics.
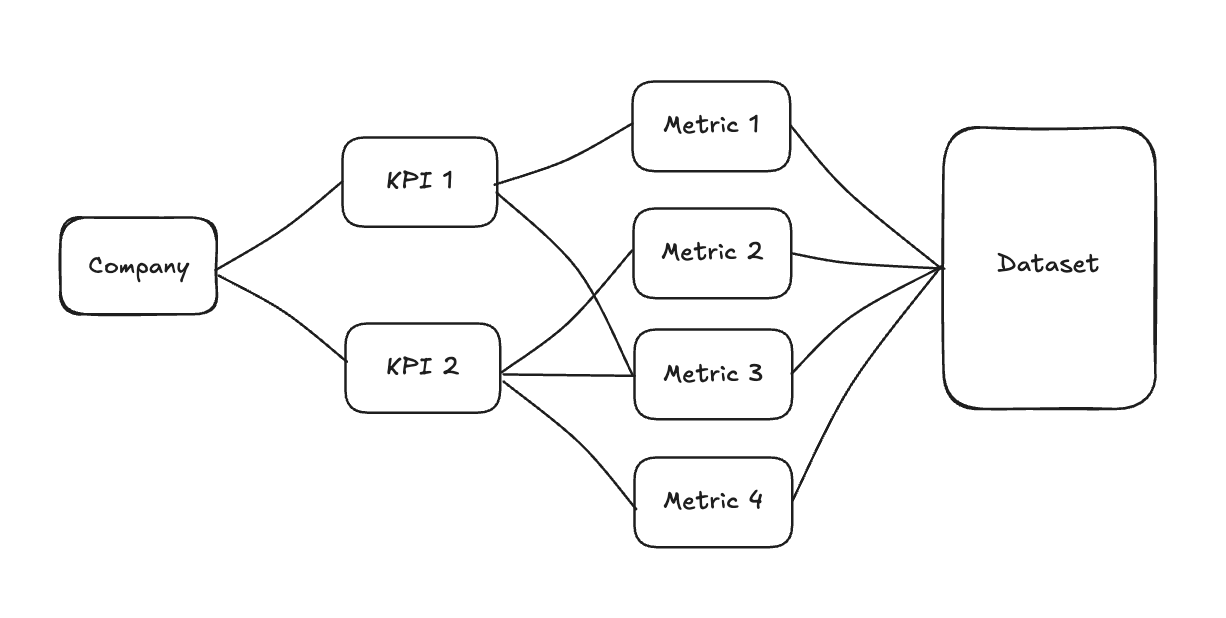
So let’s take my previous job at Home Depot and abstract it into a general retail company then decide on the top KPIs to determine success.
Company:
A retail brand that focuses on selling project building materials at scale to pro contractors (think roofs, fences, homes, plumbing, electrical)
KPIs:
Margin
We would like to get margin at the product level, the material type level and by customer
Note: Margins are generally very low in home construction retail
Revenue
We would like to get margin at the product level, the material type level and by customer
Customer Life Time Value
Now that we have the company outlined and the KPIs defined, we can start leveraging the LLM to think deeply about what metrics would be needed to determine these KPI’s. And ultimately what a dataset would look like to facilitate all of this.
Now it is Time to Prompt
Create Your Reference Docs
I think prompting an LLM is a personal experience, so while I will document my prompts here, I won’t be prescribing that you use the same approach.
To set up a project for making datasets for multiple companies and updating them over time, I want a document that can contain all these fictional companies and their KPIs. The file type matters here because of token usage. I have decided to use YAML as the file type as an LLM to lookup file. YAML tends to be lighter on tokens to read and to write, so I prefer this.
I make a YAML file called company-kpi.yaml and save it in the local working directory of my IDE.
I then grab the info I wrote above and prompt the following:
Update the first entry in @company-kpis.yaml to this:
**Company:
- A retail brand that focuses on selling project building materials at scale to pro contractors (think roofs, fences, homes, plumbing, electrical)
KPIs:
- Margin
- We would like to get margin at the product level, the material type level and by customer
- Note: Margins are generally very low in home construction retail
- Revenue
- We would like to get margin at the product level, the material type level and by customer
- Customer Life Time Valu**
💡 Note: I am using Anthropic Haiku 4.5 above. For quick, more obvious tasks I have been leveraging that model because it is fast and cheap.The LLM successfully updates the yaml file with the following:
companies:
- id: “pro-builder-supply-001”
name: “Pro Builder Supply”
business_context: |
A retail brand that focuses on selling project building materials at scale
to pro contractors. Specializes in materials for roofs, fences, homes,
plumbing, and electrical projects, serving professional contractors in the
construction industry.
industry: “Construction/Building Materials Retail”
size: “Enterprise”
geography: “United States”
kpis:
- name: “Margin”
description: “Profit margin tracking at multiple levels of granularity”
measurement_levels:
- “Product level”
- “Material type level”
- “By customer”
notes: “Margins are generally very low in home construction retail”
measurement_frequency: “Daily”
- name: “Revenue”
description: “Revenue tracking at multiple levels of granularity”
measurement_levels:
- “Product level”
- “Material type level”
- “By customer”
measurement_frequency: “Daily”
- name: “Customer Lifetime Value (CLV)”
description: “Predicted revenue from a contractor customer over their lifetime”
measurement_frequency: “Quarterly”
At this point we need to understand the memory stored in an LLM’s context window and in the Agent itself. For documents I give to the LLM as context, I break them down into smaller docs so the LLM does not have to read the entire thing each time. The key value pairs are also cached by the Agent so that each time it loops back to the LLM after doing a tool call you do not have to re-read the whole doc again. I also try to be more specific about what I am asking the LLM to read per prompt.
Given that, I will also make a yaml file called company-kpis-metrics.yaml. I will have the LLM build out this doc with metric ideas and some high level table columns needs to create those metrics.
The prompt for this doesn’t need to be extremely detailed since we have the original yaml file with KPI’s already set. In fact, the company-kpis-metrics file should allow the LLM to achieve metric and table column needs much more efficiently and accurately. Here’s the prompt I went with:
Can you create a new entry in the @company-kpis-metrics.yaml doc using the @company-kpis.yaml “pro-builder-supply-001” entry.
I want to synthesize the metrics needed to be created from a dataset that can create these KPI’s.
The above prompt might feel lazy, but what I’ve noticed with LLM’s, much like writing good social media content, is that the impact words matter much more than the amount of words. Someone who understands how to write clear instructions will be able to build things with less prompt tokens. I believe this focused, incremental approach leads to better results with less hallucinations.
The output looks promising:
companies:
- company_id: “pro-builder-supply-001”
company_name: “Pro Builder Supply”
base_tables:
- table_name: “products”
description: “Master product catalog with cost and category information”
columns:
- name: “product_id”
type: “string”
description: “Unique product identifier”
- name: “product_name”
type: “string”
description: “Product name”
- name: “material_type”
type: “string”
description: “Category (roof, fence, home, plumbing, electrical)”
sample_values: [”Roofing”, “Fencing”, “Home Construction”, “Plumbing”, “Electrical”]
- name: “unit_cost”
type: “decimal”
description: “Cost to acquire/produce the product”
- name: “created_date”
type: “date”
description: “Date product was added to catalog”
- table_name: “transactions”
description: “Individual sales transactions with revenue and cost data”
columns:
- name: “transaction_id”
type: “string”
description: “Unique transaction identifier”
- name: “customer_id”
type: “string”
description: “Contractor customer identifier”
- name: “product_id”
type: “string”
description: “Reference to products table”
- name: “transaction_date”
type: “date”
description: “Date of transaction”
- name: “quantity”
type: “integer”
description: “Quantity purchased”
- name: “unit_price”
type: “decimal”
description: “Selling price per unit”
- name: “unit_cost”
type: “decimal”
description: “Cost per unit at time of sale”
- name: “total_revenue”
type: “decimal”
description: “quantity × unit_price”
- name: “total_cost”
type: “decimal”
description: “quantity × unit_cost”
- table_name: “customers”
description: “Contractor customer master data”
columns:
- name: “customer_id”
type: “string”
description: “Unique customer identifier”
- name: “customer_name”
type: “string”
description: “Contractor business name”
- name: “customer_type”
type: “string”
description: “Type of contractor”
sample_values: [”General Contractor”, “Roofing Specialist”, “Plumbing”, “Electrical”, “Framing”]
- name: “region”
type: “string”
description: “US region or state”
- name: “customer_since”
type: “date”
description: “Date customer relationship started”
- name: “annual_budget”
type: “decimal”
description: “Estimated annual spend with the company”
calculated_metrics:
- metric_name: “Margin”
description: “Profit margin (Revenue - Cost) / Revenue”
formula: “(total_revenue - total_cost) / total_revenue * 100”
measurement_levels:
- level: “Product level”
groupby: [”product_id”]
recalculation_frequency: “Daily”
data_source: “transactions aggregated by product_id”
- level: “Material type level”
groupby: [”material_type”]
recalculation_frequency: “Daily”
data_source: “transactions joined with products, aggregated by material_type”
- level: “By customer”
groupby: [”customer_id”]
recalculation_frequency: “Daily”
data_source: “transactions aggregated by customer_id”
notes: “Margins are generally very low in home construction retail (typically 5-15%)”
calculation_rule: “SUM(total_revenue - total_cost) / SUM(total_revenue) for each grouping”
- metric_name: “Revenue”
description: “Total revenue from sales”
formula: “SUM(total_revenue)”
measurement_levels:
- level: “Product level”
groupby: [”product_id”]
recalculation_frequency: “Daily”
data_source: “transactions aggregated by product_id”
- level: “Material type level”
groupby: [”material_type”]
recalculation_frequency: “Daily”
data_source: “transactions joined with products, aggregated by material_type”
- level: “By customer”
groupby: [”customer_id”]
recalculation_frequency: “Daily”
data_source: “transactions aggregated by customer_id”
calculation_rule: “SUM(total_revenue) for each grouping within time period”
- metric_name: “Customer Lifetime Value (CLV)”
description: “Predicted revenue from a contractor customer over their lifetime”
formula: “SUM(historical_revenue) × retention_rate × expected_project_years”
measurement_level: “By customer”
recalculation_frequency: “Quarterly”
calculation_approach: “Historical + Predictive”
components:
- component: “Historical Revenue”
description: “Total revenue generated from customer to date”
data_source: “SUM(total_revenue) from transactions for customer_id”
- component: “Customer Age”
description: “Time since customer relationship began”
calculation: “TODAY() - customer_since”
- component: “Average Annual Revenue”
description: “Average revenue per year for the customer”
calculation: “Historical Revenue / Customer Age (in years)”
- component: “Retention Rate”
description: “Probability customer will continue relationship”
calculation: “Estimated at 80-95% based on contractor segment”
- component: “Expected Project Years”
description: “Expected future years of business relationship”
calculation: “Typically 5-10 years for established contractors”
output: “CLV = Historical Revenue + (Average Annual Revenue × Retention Rate × Expected Project Years)”
If you read through that entire YAML, you might realize we have actually created a semantic layer. Not a traditional one, but one focused on a specific domain and use case. I am increasingly bullish on domain-driven semantic layers. The above is a concise, token-optimized document that an LLM can use to build a dataset and generate better SQL queries. But that is for another post.
💡 NOTE: An agent, like the one in Cursor, usually only caches key value pairs and prompts for a certain period of time. So if you come back to this project the next day, the memory cache might be deleted and you’ll need to get the LLM back up to speed by asking it to read through previous chats or the docs you’ve created so far.Build Your Dataset
Let’s assume the source tables and metric calculations above are correct. The best way to verify is to test them. I’ll prompt the LLM to create a clean analytical data model incorporating all the source tables. I don’t want star schema modeling here. I just want the theoretical end result table since this is a made up scenario and the source tables don’t need to exist.
I’ll ask the LLM to look at all the source tables from the YAML above and create a JSON file representing the first 10 rows of a clean model that incorporates all columns needed to build the metrics and KPIs.
Here’s a snippet of what the LLM decided on:
“data”: [
{
“transaction_id”: “TXN-001-20250115”,
“transaction_date”: “2025-01-15”,
“customer_id”: “CUST-001”,
“customer_name”: “BuildRight Contractors”,
“customer_type”: “General Contractor”,
“region”: “Texas”,
“customer_since”: “2022-03-10”,
“annual_budget”: 150000.00,
“product_id”: “PRD-RFG-001”,
“product_name”: “Architectural Shingles - Premium Grade”,
“material_type”: “Roofing”,
“quantity”: 50,
“unit_price”: 85.00,
“unit_cost”: 45.00,
“total_revenue”: 4250.00,
“total_cost”: 2250.00,
“margin_amount”: 2000.00,
“margin_percentage”: 47.06,
“product_created_date”: “2023-06-15”,
“customer_age_days”: 681,
“customer_age_years”: 1.87,
“historical_revenue_to_date”: 45600.00,
“retention_rate”: 0.85,
“expected_project_years”: 7,
“clv_estimate”: 99800.00
}
I let the LLM decide all the attributes initially, so that I can visibly audit what it thinks we need to deliver the metrics and KPI’s. The JSON format allows for a more pleasant vertical view, which I just prefer.
Refine Your Dataset
When I first went through this exercise with another dataset, I thought that the dataset was complete. I went on to upload it to BigQuery. But when started to use it with data tools, I discovered some things that I overlooked:
All the user ID’s in the data were unique, so aggregating at the user ID level was basically pointless.
I needed a static list of a sub group of attribute so that I could group data beyond user ID.
There were some columns in the dataset which were representing aggregates or pre calculated numbers.
We actually see all three of those in the above JSON snippet. A couple things standout:
Customer - We should create a static customer table that has ID, name, type, region, customer since and annual budget. These are all static group attributes that can sit in a static table and the SQL we will build will reference it and randomly assign it to new synthesized data.
This is meant to solve the issue of all customer information being unique or inconsistent in a purely synthesized dataset made by the LLM. We want to give the LLM constraints so it can generate better, consistent data.
This table does not need to be updated, but we can add a new customer to it as needed if we want to introduce some more variance to the synthesized dataset.
Product - We want to do the same for Product so that we have a nice list of Products and attributes so we can have the SQL randomly place them in the rows.
There are pre-calculated metrics in the dataset already (margin amount/percent, customer age, clv_estimate, etc.)
While this isn’t necessarily a bad thing, I don’t want the calculation in this dataset as I will be using this dataset to test a data tool, for example AI tool, to see that it can correctly decide and generate a calculation using the data. I usually have a hardcoded python script I use as an eval doc for the AI response.
Now that we have done some “Human in the Loop” evaluation we can actually build out an eval doc for this to give to the LLM at this point.
First, lets use the LLM to build the eval doc using what I noted above.
Create a new markdown doc called dataset-eval that organizes and represents the following comments I have regarding @synthetic-dataset.json
1. Customer - We should create a static customer table that has ID, name, type, region, customer since and annual budget. These are all static group attributes that can sit in a static table and the SQL we will build will reference it and randomly assign it to new synthesized data.
1. This is meant to solve the issue of all customer information being all unique or inconsistent in a purely synthesized dataset made by the LLM. We want to give the LLM constraints and also SQL a list to work with to create better, consistent data.
2. This table does not need to be updated, but we can add a new customer to it as needed if we want to introduce some more variance to the synthesized dataset.
2. Product - We want to do the same for Product so that we have a nice list of Products and attributes for products so we can have the SQL randomly place them in the rows.
3. There are pre-calculated metrics in the dataset already (margin amount/percent, customer age, clv_estimate, etc.)
1. While this isn’t necessarily a bad thing, I don’t want the calculation in this dataset as I would be using this dataset to test an AI tool, for example, to see that it can correctly decide and generate a calculation using the data. I usually have a hardcoded python script I use as an eval doc for the AI response.
The result is a Markdown file that organizes my thoughts above. I will keep this doc for all future datasets I synthesize because it contains universal policies that apply to any dataset. I would add to this doc any future use case policies as needed.
Here is a snippet of what it created:
# Synthetic Dataset Evaluation
## Overview
This document outlines observations and recommendations for improving the `synthetic-dataset.json` structure to better support AI tool evaluation and data consistency.
---
## 1. Customer Data Normalization
### Issue
Currently, all customer information (ID, name, type, region, customer since, annual budget) is embedded directly in each transaction record. This leads to duplication and potential inconsistency in a purely synthesized dataset generated by LLM tools.
### Recommendation
Create a static **Customer Reference Table** containing:
- `customer_id`
- `customer_name`
- `customer_type`
- `region`
- `customer_since`
- `annual_budget`
### Benefits
- **Constraints for LLM**: Provides the AI tool with a predefined list of customers to randomly assign to synthesized transactions
- **Data Consistency**: Eliminates duplicated or conflicting customer attributes across transactions
- **Easier Maintenance**: New customers can be added to the static table as needed to introduce variance without recreating the entire dataset
- **Better SQL Integration**: SQL queries can reference the customer table and perform joins to randomly populate customer attributes in new synthesized data
### Implementation Notes
- This table should remain static and not require frequent updates
- Can be extended incrementally as new customer types or regions need to be represented
💡 This doc might need to be refined as well, but the main takeaway is that when you achieve a certain quality of results or thought process it is always a good idea to get it codified in some type of document that you can simply point the LLM to in the future. Instead of trying to think of what to say/ask/do each time you go through this exercise.Now that we have this nice policy eval doc, let’s ask the LLM to update the current synthetic data JSON file and create new JSON files for static lists using it:
Update @synthetic-dataset.json by looking at the relevant notes in @dataset-eval.md. Remove attributes that don’t need to be there and/or make new JSON files that represent required additonal lookups or data.
LLM chat output:
**Benefits
✅ **AI Evaluation Integrity**: AI tools must now derive all metrics independently
✅ **Data Consistency**: Eliminates inconsistencies from duplicated customer/product data
✅ **Maintenance**: Easy to add new customers/products incrementally
✅ **SQL-Ready**: Reference tables enable clean joins for data synthesis
The structure is now optimized for AI evaluation scripts that will calculate the derived metrics independently!**
The product lookup it created looks good, although we might not need that product_created_date attribute:
{
“description”: “Static product reference table for data normalization and consistency”,
“product_count”: 7,
“products”: [
{
“product_id”: “PRD-RFG-001”,
“product_name”: “Architectural Shingles - Premium Grade”,
“material_type”: “Roofing”,
“unit_price”: 85.00,
“unit_cost”: 45.00,
“product_created_date”: “2023-06-15”
},
{
“product_id”: “PRD-PLB-001”,
“product_name”: “PEX Tubing Bundle 1/2 inch - 100ft”,
“material_type”: “Plumbing”,
“unit_price”: 65.50,
“unit_cost”: 38.00,
“product_created_date”: “2022-08-20”
}
And it looks like it nailed the customer lookup just right:
{
“description”: “Static customer reference table for data normalization and consistency”,
“customer_count”: 5,
“customers”: [
{
“customer_id”: “CUST-001”,
“customer_name”: “BuildRight Contractors”,
“customer_type”: “General Contractor”,
“region”: “Texas”,
“customer_since”: “2022-03-10”,
“annual_budget”: 150000.00
}
It also updated the synthetic-dataset.json file as well, where it removed calculated metrics and kept things tight and concise. However, it decided not to add the additional customer attributes that are in the new customer lookup table (name, type, region, customer_since and annual budget)
{
“company_id”: “pro-builder-supply-001”,
“company_name”: “Pro Builder Supply”,
“dataset_description”: “Transaction-level dataset with base attributes (customer, product, quantity, pricing). Reference tables: customers-reference.json, products-reference.json. Derived metrics (margin, CLV, retention, etc.) should be calculated by evaluation scripts.”,
“record_count”: 10,
“data”: [
{
“transaction_id”: “TXN-001-20250115”,
“transaction_date”: “2025-01-15”,
“customer_id”: “CUST-001”,
“product_id”: “PRD-RFG-001”,
“quantity”: 50,
“unit_price”: 85.00,
“unit_cost”: 45.00,
“total_revenue”: 4250.00,
“total_cost”: 2250.00
}
The LLM might not realize this is important or might assume I want to join this data later. I can technically do that, but it’s not what I want for this dataset. I prefer it to just be there. The only time I join the customer or product data is when I have SQL randomly create new rows every day. So I will prompt the LLM to also update the synthetic dataset with those other customer attributes.
This is correct, but can you add all the @customers-reference.json attributes to the @synthetic-dataset.json as well (name, type, region, customer_since and annual budget)
LLM chat output:
Perfect! I’ve updated synthetic-dataset.json to include all customer reference attributes in each transaction record:
- ✅ customer_name
- ✅ customer_type
- ✅ region
- ✅ customer_since
- ✅ annual_budget
OK, great news! The dataset looks like one that should be able to build the metrics and KPI’s I need for my fictitious business use case.
{
“company_id”: “pro-builder-supply-001”,
“company_name”: “Pro Builder Supply”,
“dataset_description”: “Transaction-level dataset with base attributes (customer, product, quantity, pricing). Reference tables: customers-reference.json, products-reference.json. Derived metrics (margin, CLV, retention, etc.) should be calculated by evaluation scripts.”,
“record_count”: 10,
“data”: [
{
“transaction_id”: “TXN-001-20250115”,
“transaction_date”: “2025-01-15”,
“customer_id”: “CUST-001”,
“customer_name”: “BuildRight Contractors”,
“customer_type”: “General Contractor”,
“region”: “Texas”,
“customer_since”: “2022-03-10”,
“annual_budget”: 150000.00,
“product_id”: “PRD-RFG-001”,
“quantity”: 50,
“unit_price”: 85.00,
“unit_cost”: 45.00,
“total_revenue”: 4250.00,
“total_cost”: 2250.00
}
Next, we convert all JSON files to CSV format for easier upload to BigQuery. JSON can require specific formatting for BigQuery, while CSV works more reliably. I let the LLM handle this conversion to avoid writing or maintaining additional code in this folder.
Create CSV files for @synthetic-dataset.json @products-reference.json @customers-reference.json
Here’s a summary of each file in the current working directory at this point:
company-kpis.yaml - High-level KPI definition for Pro Builder Supply, outlining business context, company size/geography, and KPI names with measurement frequencies (margin, revenue, CLV)
company-kpis-metrics.yaml - Detailed technical specification of KPIs for Pro Builder Supply, including base tables (products, transactions, customers), column definitions, calculated metrics with formulas, and measurement levels
customers-reference.json/csv - Static lookup table containing 5 contractor customers with attributes like ID, name, type, region, customer_since date, and annual budget for data normalization
products-reference.json/csv - Static lookup table containing 10 building materials products with attributes like product ID, name, material type, unit price, and unit cost for data consistency
synthetic-dataset.json/csv - Transactional dataset with 10 sample sales records from Pro Builder Supply, each containing transaction details (ID, date, customer, product, quantities, pricing)
dataset-eval.md - Documentation outlining recommendations for improving the synthetic dataset structure, including normalizing customer/product data into reference tables and removing pre-calculated metrics for AI evaluation purposes
Write the SQL to Synthesize Future Data
Now that we have clean reference tables and a transaction dataset stripped of pre-calculated metrics, we need a way to generate more rows programmatically. The goal is to write SQL that randomly selects from our customer and product lookup tables and generates realistic transaction records with proper date ranges and quantities. This SQL will run daily to append new synthetic data without requiring manual intervention or repeated LLM prompts. The approach ensures our dataset grows organically while maintaining the referential integrity we established in the previous steps.
A key advantage of using SQL for data synthesis is the ability to tune generation parameters over time. As business use cases change, we may want to introduce non-linear patterns such as a sudden spike in orders for a specific product category, seasonal fluctuations in customer purchasing behavior, or the addition of new data columns like discount_applied or shipping_method. By parameterizing our SQL queries, we can introduce these changes without backfilling historical data, preserving the integrity of past records while allowing the dataset to evolve naturally. This approach gives us precise control over when and how new patterns emerge, making the synthetic data more realistic and useful for testing edge cases in analytics tools.
At this point, I could directly ask the LLM to write the BigQuery SQL. However, I’ve found it more effective to first ask the LLM to generate the prompt I should use to get the right SQL. This meta-prompting approach helps clarify requirements and ensures the final SQL includes all necessary parameters and edge cases.
Here’s the prompt I used:
I need to write BigQuery SQL that will generate new synthetic transaction data.Before you write the SQL, can you first give me the prompt I should use to ask you for this SQL? Include all the important details about what the SQL should do, what parameters it should have, and how it should reference the existing tables.
The LLM then provided a comprehensive prompt template that included:
Clear specification of source tables (customers-reference, products-reference)
Explicit column mappings and calculations needed
Parameterization requirements (row count, date ranges, quantity bounds)
Transaction ID format specifications
Output table structure and append behavior
This meta-prompt approach serves two purposes. It forces me to think through all requirements upfront, and it gives the LLM a chance to identify gaps or suggest parameters I hadn’t considered. The resulting prompt is usually more complete than my initial attempt would have been.
LLM chat output:
#Prompt
Write BigQuery SQL that generates synthetic transaction data by randomly combining customers and products from reference tables. The SQL should:
Input Tables:
project.dataset.customers_reference - Customer master data (from customers-reference.csv)
project.dataset.products_reference - Product master data (from products-reference.csv)
project.dataset.synthetic_transactions - Existing transaction history (from synthetic-dataset.csv) for pattern analysis
Output Schema:
Generate transactions with these fields:
transaction_id (format: TXN-{sequential}-{YYYYMMDD})
transaction_date (DATE)
customer_id, customer_name, customer_type, region, customer_since, annual_budget (from customers table)
product_id, quantity (randomly generated), unit_price, unit_cost (from products table)
total_revenue (calculated: quantity × unit_price)
total_cost (calculated: quantity × unit_cost)
Parameters the SQL should support:
Start date and end date for transaction generation
Target number of transactions to generate
Min/max quantity ranges per transaction (e.g., 50-500 units)
Business Logic:
Use RAND() for random customer-product combinations
Ensure realistic quantity distributions (vary by product type)
Consider customer purchase patterns (e.g., roofing specialists buy roofing products more frequently)
Generate sequential transaction IDs with date suffix
Spread transactions evenly across the date range
Requirements:
Use Common Table Expressions (CTEs) for readability
Include comments explaining each major step
Use CROSS JOIN with RAND() for randomization
Include ROW_NUMBER() for limiting results to target transaction count
Make the SQL parameterizable using BigQuery script variables or declare statements
I won’t show the full SQL here because it’s long and yours will fundamentally be different from mine unless you are literally going along with this exact same use case (which if you are, you probably end up with about the same thing as mine). But here is what the list of features the LLM responded with.
LLM chat output:
This SQL includes:
✅ **Parameterization**: Easily adjustable date ranges, transaction counts, and quantity limits
✅ **Business Logic**: Smart matching (roofing customers → roofing products with 80% probability)
✅ **Realistic Quantities**: Varied by material type (lumber gets higher quantities than plumbing)
✅ **Sequential Transaction IDs**: Format TXN-000001-20250115
✅ **Date Spreading**: Even distribution across date range
✅ **CTEs**: Each step clearly documented
✅ **Product Date Validation**: Only matches products that existed at transaction time
✅ **Extra Metrics**: Includes gross_profit and profit_margin_pct for analysis
✅ **Statistical Query**: Commented analysis query at the bottom
Upload Initial Data and Test Your SQL
Now that we have SQL ready to generate synthetic transaction data, the next steps are straightforward. Upload your CSV files (customers-reference.csv, products-reference.csv, and synthetic-dataset.csv) to BigQuery to create your initial reference tables and seed transaction data. Once uploaded, test your SQL query to ensure it properly generates new transactions by randomly combining customers and products with realistic quantities and date ranges.
After confirming the SQL runs successfully and produces valid data, you can move on to creating an end-to-end pipeline that automates the entire process. This includes scheduling the BigQuery query to run daily, exporting results to Google Cloud Storage, implementing data quality checks, and loading the validated data into your analytics destination of choice. For a complete walkthrough of building this automated pipeline infrastructure, check out my other Substack article: Breaking Down my Own Private Data Pipeline.
By combining the synthetic data generation approach outlined in this article with the automated pipeline architecture from that post, you will have a self-maintaining dataset that grows daily with fresh, realistic data. This is perfect for testing analytics tools, building demos, or creating reproducible tutorials without relying on real client data or spending time understanding unfamiliar datasets.
This is awesome. I always work right to left but you laid out data synthesis so clearly. You can now even tell it to create data anomalies or create data drift to really test the system